{kind=link}
360开源高质量图文对齐数据集!收纳1200万张图像+1000万组细粒度负样本,让模型告别“图文不符”
如何让 CLIP 模型更关注细粒度特征学习,避免 " 近视 "?
360 人工智能研究团队提出了FG-CLIP,可以明显缓解 CLIP 的 " 视觉近视 " 问题。
让模型能更关注于正确的细节描述,而不是更全局但是错误的描述。

模型成功的关键在于高质量数据。
就在最近,冷大炜博士团队将这一 " 秘籍 " 开源:FineHARD 高质量图文对齐数据集。该数据集主打两个核心特点:细粒度 + 难负样本。
FineHARD 是 FG-CLIP 模型背后的高质量图文对齐数据集,以规模化与精细化为特色,包含 1200 万张图像及其对应的长、短描述文本,覆盖4000 万个边界框,每个边界框均附带细粒度区域描述(Fine-Grained Regional Description)。
此外,FineHARD 创新性地引入了1000 万组细粒度难负样本(Hard Fine-grained Negative Samples),这些经过算法筛选的干扰样本能够有效提升模型对相似目标的区分能力。
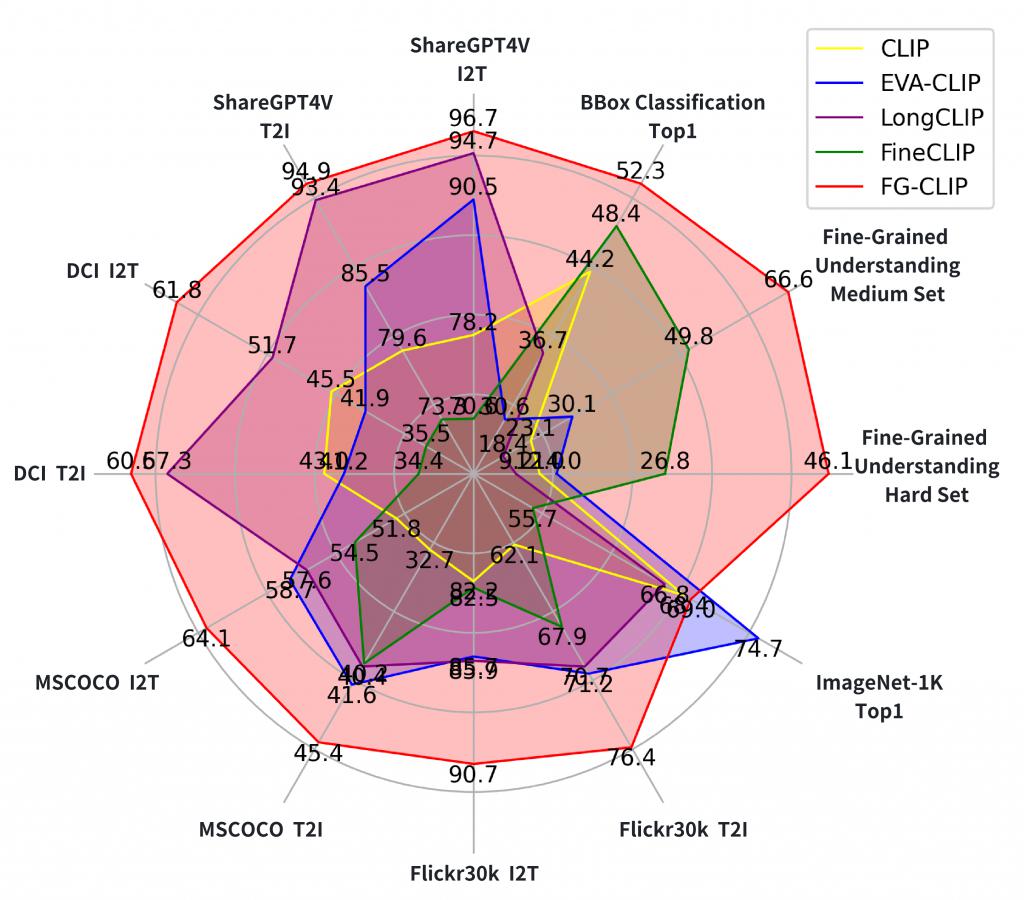
基于该数据集训练的 FG-CLIP 已被 ICML25 接收,它在各种下游任务中显著优于原始 CLIP 和其他最先进方法,包括细粒度理解、开放词汇对象检测、长短文本图文检索以及通用多模态基准测试等。
细粒度 + 难负样本
具体来看,FineHARD 数据集主要包含以下三方面工作。
全局细粒度对齐:FineHARD 数据集不仅包含了常规的图像 " 短文本 " 描述(平均长度约 20 个词),同时为了弥补短文本描述细节缺失的问题,FG-CLIP 团队基于多模态 LMM 模型为数据集中的每张图像生成了包含场景背景、对象属性及空间关系等详细信息的 " 长文本 " 描述(平均长度 150 个词 +),显著提升了全局语义密度。
局部细粒度对齐:" 长文本 " 描述主要从文本侧为细粒度对齐打好了数据基础,为了进一步从图像侧也提升细粒度能力,FG-CLIP 团队为 FineHARD 数据集中的每张图像进行基于开放世界目标检测模型提取了图像中大部分目标实体的位置,并为每个目标区域匹配了对应的 region 描述。FineHARD 数据集包含高达 4000 万个 bounding box 及其对应的区域级细粒度描述文本。
细粒度难负样本:在上述全局细粒度对齐和局部细粒度对齐的基础上,为了进一步提高模型对图文细节的对齐理解和区分能力,FG-CLIP 团队基于细节属性扰动方法,利用 LLM 模型为 FineHARD 数据集构造并清洗出了 1000 万组细粒度难负样本。大规模难负样本数据是 FineHARD 数据集区别于已有数据的第三个重要特点。
FineHARD 数据集构建
FineHARD 数据集以 1200 万张高质量图像为核心基底,每张图像均配备精准的语义描述文本。数据集包含 4000 万个边界框标注,每个边界框均附带区域级细粒度描述(Fine-Grained Regional Description),并通过算法筛选整合了 1000 万组细粒度难负样本。在数据预处理阶段,团队采用分布式计算架构,依托 160 × 910B 算力的 NPU 集群,在 7 天内完成数据清洗、特征提取及多模态对齐等核心操作,实现了从原始图像到结构化数据的高效转化。
多模态描述生成机制
FineHARD 的文本描述体系基于 GRIT 数据集进行深度优化。首先通过严格筛选保留 1200 万张代表性图像,随后引入幻觉信息较小的多模态大模型 CogVLM2-19B,为每张图像生成包含场景背景、对象属性及空间关系的长描述文本。相较原始 GRIT 数据集的简短概括式描述(平均长度约 20 词),本数据集的文本描述平均扩展至 150 词以上,显著提升了语义密度与场景还原度。这种描述体系既保留了原始数据集的通用性,又通过精细化标注增强了语义表达能力。
边界框与语义描述的协同构建
基于生成的长描述文本,采用自然语言处理工具 spaCy 进行指代表达(如 " 红色汽车 "、" 左上角的瓶子 ")的提取与解析。原始 GRIT 数据集虽提供基础边界框,但存在类别覆盖不全(如部分图像仅标注人)等问题。为此,FG-CLIP 团队设计了双重增强策略:
细粒度描述补充:对基础边界框补充细粒度指代描述。
目标检测扩展:通过预训练的 Yolo-World 模型对图像与指代表达进行联合推理,生成额外边界框。采用非极大值抑制(NMS)技术过滤重叠区域,仅保留置信度>0.4 的高质量预测结果。
最终构建出包含区域级语义描述的 4000 万边界框体系,实现视觉元素与语义信息的精准对齐。


细粒度负样本生成与质量验证
为提升模型对相似目标的判别能力,FG-CLIP 团队开发了基于属性扰动的负样本生成方案。具体流程如下:
属性修改策略:在保持对象名称一致的前提下,通过开源大语言模型 Llama-3.1-70B 对正样本描述进行属性替换(如将 " 红色汽车 " 改为 " 蓝色汽车 "),生成 10 个属性相似但语义不同的负样本;
文本规范化处理:移除特殊符号(分号、逗号、换行符等),确保描述格式统一性;
质量评估体系:对 3000 个样本进行人工复核,结果显示 98.9% 的样本符合质量标准,仅 1.1% 被判定为噪声——该误差率处于无监督生成方法的合理阈值范围内。
此类细微语义差异的负样本更贴近真实场景中物体外观相似但属性不同的复杂情况,使模型在视觉定位任务中具备更强的鲁棒性。

FineHARD 数据集分析常见数据集对比
为了定量分析 FineHARD 数据集的特点,我们与一些业界常用的数据集,如 Flickr30k,CC3M 和 COCO 在图像,文本描述,目标 bounding box 和难负样本等四个维度进行了对比,如下图所示。
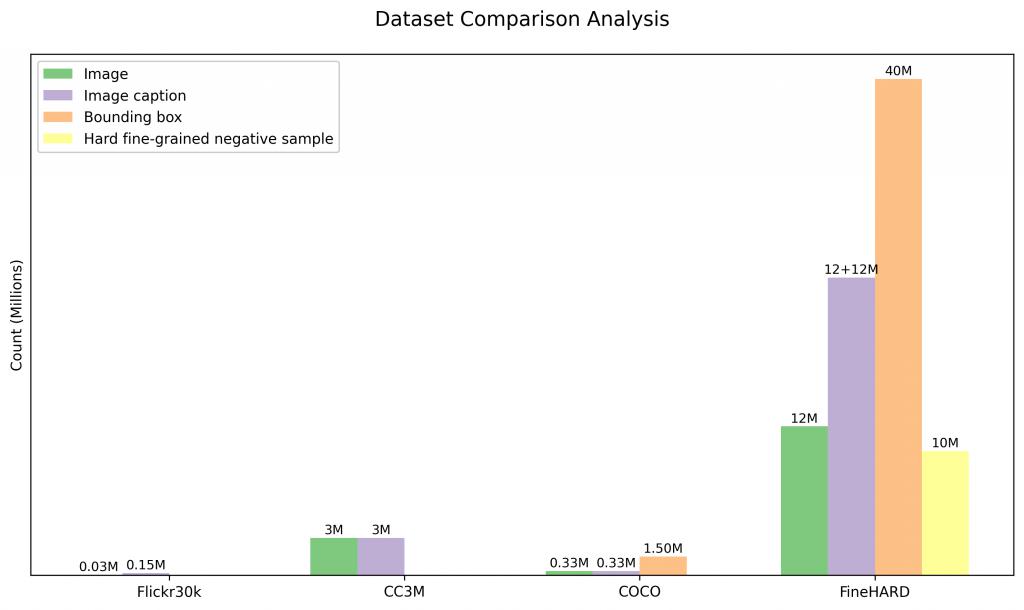
FineHARD 数据集在规模和质量方面表现尤为突出,特别是在细粒度标注和具有挑战性的负样本方面。在规模上,FineHARD 涵盖了 1200 万张图像、4000 万个边界框以及相应的描述,数量远超同类数据集。例如,与广泛使用的 COCO 数据集相比,后者仅提供 150 万个边界框,而 FineHARD 数据集则拥有 4000 万个边界框,极大地丰富了对象定位和识别的训练资源。此外,FineHARD 数据集的一个显著特色是包含了 1000 万个难例细粒度负样本,这些样本经过精心设计以帮助模型更好地分辨语义相似对象间的细微差异,从而有效提升其在各种下游任务中的性能表现。通过这样的综合构建,FineHARD 数据集不仅在数量上占据优势,同时也在质量上为高级视觉理解和目标检测技术的发展提供了坚实基础。
细粒度数据集对比
我们进一步将其与其他专门的细粒度数据集(如 LVIS 和 V3Det)进行了对比。FineHARD 通过 CogVLM2-19B 和 YOLO-World 生成的 region 描述中提取并汇总了类别标签,以构建数据集中所涵盖的对象类别信息。下表展示了不同数据集在图像数量、文本描述数量与由不同文本描述归纳出的独立类别标签数量的对比,注意因为差距悬殊,横纵坐标均为对数坐标:

为了进一步分析 FineHARD 数据集的样本多样性,我们随机采样了与 V3Det 相同图像规模(243,000 张)的子集进行对比,在这个子集中,FineHARD 包含了 21k 个独立类别标签,显著高于 V3Det 的 13k 个,表明 FineHARD 数据集在语义覆盖范围和多样性方面具有明显优势。此外,我们使用 t-SNE 降维方法对采样数据的类别标签进行可视化展示:

该图进一步验证了在相同图像规模下,FineHARD 数据集呈现出更广泛的类别分布,说明其在视觉语义上的丰富性和更高的多样性。随着数据集扩展至 1,200 万张图像,类别标签和描述文本的多样性进一步显著提升。这种规模的增长不仅增强了模型对稀有类别的学习能力,也为细粒度视觉理解任务提供了更全面的数据支撑。这标志着 FineHARD 在构建大规模、高质量、高多样性视觉语言数据集方面迈出了重要一步。
可应用于具身智能、3D 建模等领域
从技术应用前景看,FineHARD 数据集将对多个前沿领域产生影响:
多模态大模型训练:通过海量图文 - 区域对齐数据的预训练,可显著提升模型的跨模态理解与生成能力,特别是对图像细节的理解与对齐;
具身智能系统开发:结合细粒度空间描述与动作语义,为机器人提供更精准的环境感知与操作指令解析能力,推动工业自动化向认知决策层面升级;
3D 场景建模与数字孪生:区域级细粒度描述可作为语义特征点云的生成依据,为虚拟场景重建提供高精度语义锚点,加速 AR/VR 等沉浸式技术发展;
细粒度识别突破:通过难负样本的对抗训练,可有效提升模型对近似类别(如不同型号汽车、相似品种花卉)的判别能力,推动安防、零售等场景的落地应用。
项目 Github:https://github.com/360CVGroup/FG-CLIP
数据集地址:https://huggingface.co/datasets/qihoo360/FineHARD
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
点亮星标
科技前沿进展每日见