{kind=link}
带图推理碾压同类开源模型!港中文微软等开源OpenThinkIMG框架,教AI学会使用视觉工具
教 AI 学会使用工具,带图推理就能变得更强?!
港中文、微软联合 8 家单位推出OpenThinkIMG 开源框架,这是一个专为提升 AI 视觉工具使用和推理能力而设计的一站式平台。

众所周知,我们人类在解决问题时,常常会借助视觉工具:解几何题时画辅助线,分析图表时用荧光笔标记。这些 " 动手 " 操作,极大地增强了我们的认知和推理能力。
因此,一旦将同款 " 动手操作 " 能力赋予 AI,其推理能力也将大大提升。
不过问题是,虽然现在已经有很多强大的视觉工具(分割、检测、OCR 等),但让 AI 真正学会如何以及何时智能地使用这些工具,却面临巨大挑战:
工具集成难:不同工具接口各异,想把它们整合到一个 AI 系统里,费时费力。
训练数据缺:教 AI 用工具,需要大量 " 示范操作 " 数据。这种数据怎么来?质量如何保证?
模型适应差:传统方法训练出的 AI,往往只会 " 照本宣科 ",遇到新情况就傻眼,缺乏灵活应变和自主学习的能力。
而 OpenThinkIMG 框架的出现正是为了解决上述问题,与此同时,团队还公开了其核心的自适应工具使用训练技术V-ToolRL。
下面具体来看。
OpenThinkIMG:为 AI 打造的 " 超级工具箱 "
如框架图所示,OpenThinkIMG 集工具部署、数据生成、智能体训练于一体。
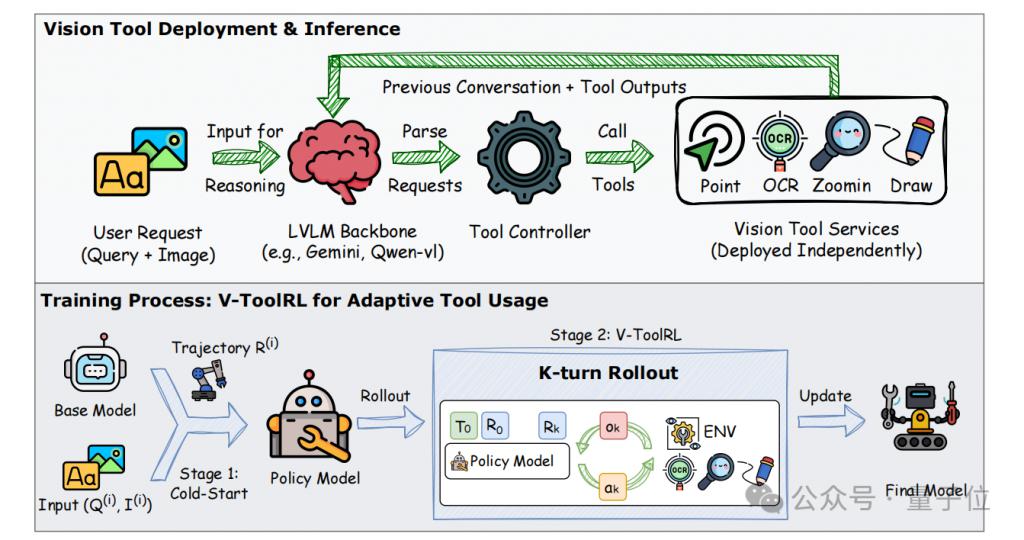
其核心特性如下:
第一,模块化视觉工具部署 ( Tool Deployment ) 。
简单来说,它提供标准化的视觉工具接口,无论是已有的成熟工具(如 GroundingDINO, SAM, OCR 等),还是你自己的新工具,都能轻松接入 OpenThinkIMG 的 " 工具箱 "。
并且每个工具都可以作为独立服务部署,互不干扰,方便管理和按需扩展。AI 模型可以通过框架内的 " 工具控制器 " 按需调用。
第二,高效的智能体训练框架 ( Training Framework ) 。
它不仅支持传统的监督微调 ( SFT ) ,更集成了团队创新的 V-ToolRL ( Visual Tool Reinforcement Learning ) 算法。
这一算法让 AI 通过强化学习,在与视觉工具的真实交互中,从错误中学习,自主探索和掌握最佳的工具使用策略。
具体而言,需要先通过 SFT 进行 " 理论学习 "(冷启动),然后通过 V-ToolRL 进行 " 上路实操 ",根据任务完成情况获得奖励或惩罚,不断优化策略。
第三,支持高质量训练数据生成 ( Scalable Trajectory Generation ) 。
为了给 V-ToolRL 提供优质的初始 " 教材 ",OpenThinkIMG 内置了一套团队提出的高效、可扩展的视觉工具使用轨迹生成方法。
具体过程分为三步:
AI 规划师 ( GPT-4o ) 出马:先让大模型规划出解决问题的初步工具步骤。
工具真实执行与记录:调用 OpenThinkIMG 中的工具服务,实际执行规划,并记录下每一步的输入输出。
严格质检与筛选:结合 AI 模型(如 Qwen2-VL-72B)、规则和人工审查,层层把关,确保数据质量。

△高质量视觉轨迹数据构建流程
通过 OpenThinkIMG 的这些核心能力,研究者和开发者可以更专注于模型算法的创新,而不必在工具部署和数据准备上耗费过多精力。
OpenThinkIMG + V-ToolRL:表现超过 GPT-4.1
团队在具有挑战性的图表推理任务上,使用 OpenThinkIMG 框架训练了基于 V-ToolRL 的智能体。
如图所示,V-ToolRL 在 ChartGemma 测试集上的性能表现(基于 OpenThinkIMG 训练)如下:
1、大幅超越 SFT:基于一个 2B 的 Qwen2-VL,经过 V-ToolRL 训练后,准确率比单纯 SFT 提升了28.83个百分点;
2、碾压同类开源模型:V-ToolRL 的表现平均超过了如 Taco、CogCom 等基于监督学习的工具使用基线12.7个百分点,而且团队的模型参数量更小;
3、媲美顶尖模型:V-ToolRL 的表现超过 GPT-4.1,同时和 Gemini 达到持平的效果。
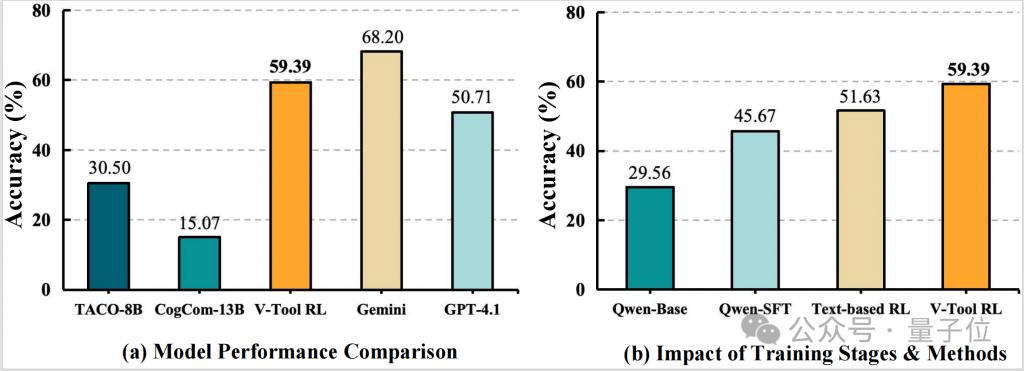
结果充分证明了 OpenThinkIMG 框架的强大支撑能力,以及 V-ToolRL 在学习自适应工具调用策略上的优越性。
那么,V-ToolRL 是如何在 OpenThinkIMG 中学习的呢?
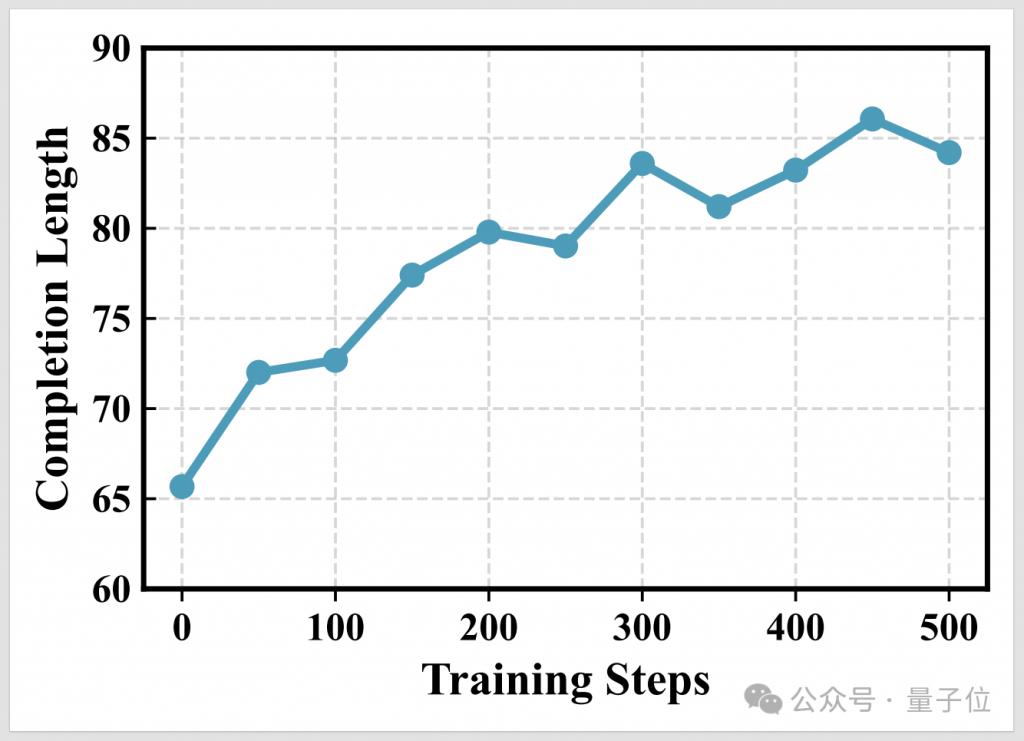
通过 OpenThinkIMG 的训练环境,团队观察到 V-ToolRL 智能体展现出以下学习特性: ( a ) 工具调用更高效 ( b ) 推理更详尽 ( c ) V-ToolRL 学习更快更好。
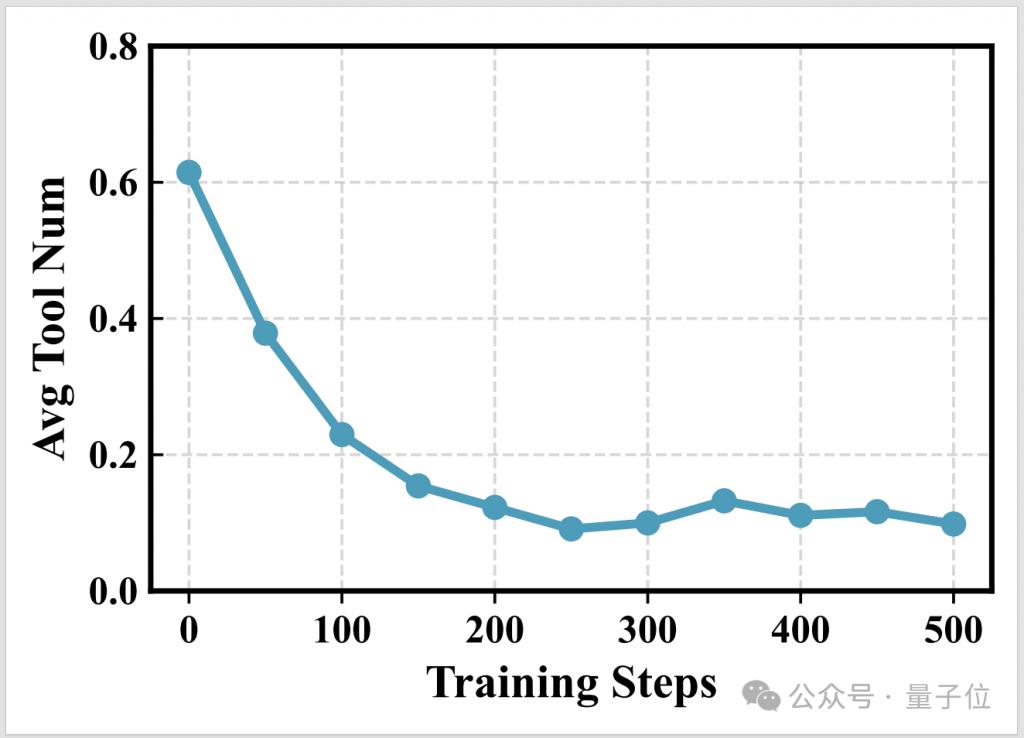
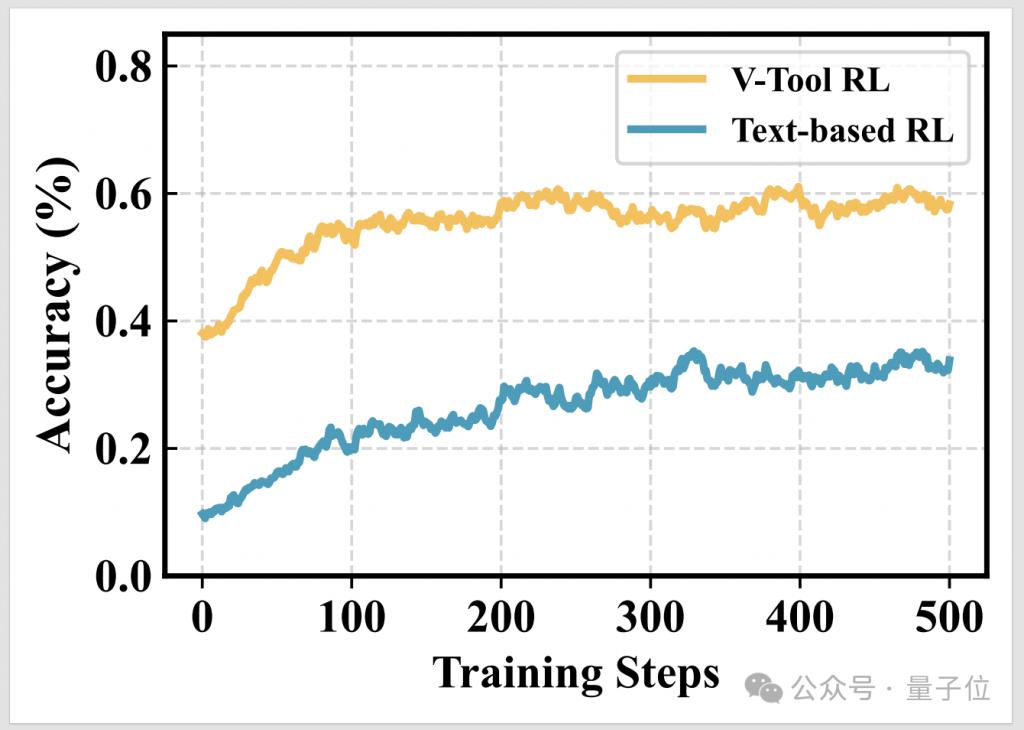
具体而言,随着训练的进行,模型平均调用的工具次数显著下降,说明它学会了 " 好钢用在刀刃上 ",只在必要时才使用工具。
而且模型生成的答案(包括思考过程)长度增加了,表明它能够进行更详细、更深入的推理。
最后,V-ToolRL(集成了视觉工具的反馈)相比纯文本的强化学习,学习速度更快,最终效果也更好,证明了 " 眼见为实 " 的重要性。
下图展示了 V-ToolRL 在具体问题上的表现。面对复杂的图表,V-ToolRL 能够:
饼图分析 ( 上 ) :通过 ZoomInSubfigure 放大关键区域,再用 OCR 精准读取数值,最终正确计算出差异,而直接解读的模型则容易出错。
折线图趋势 ( 下 ) :利用 Point 定位数据点,DrawVerticalLineByX 辅助比较,准确找出趋势相同的类别。
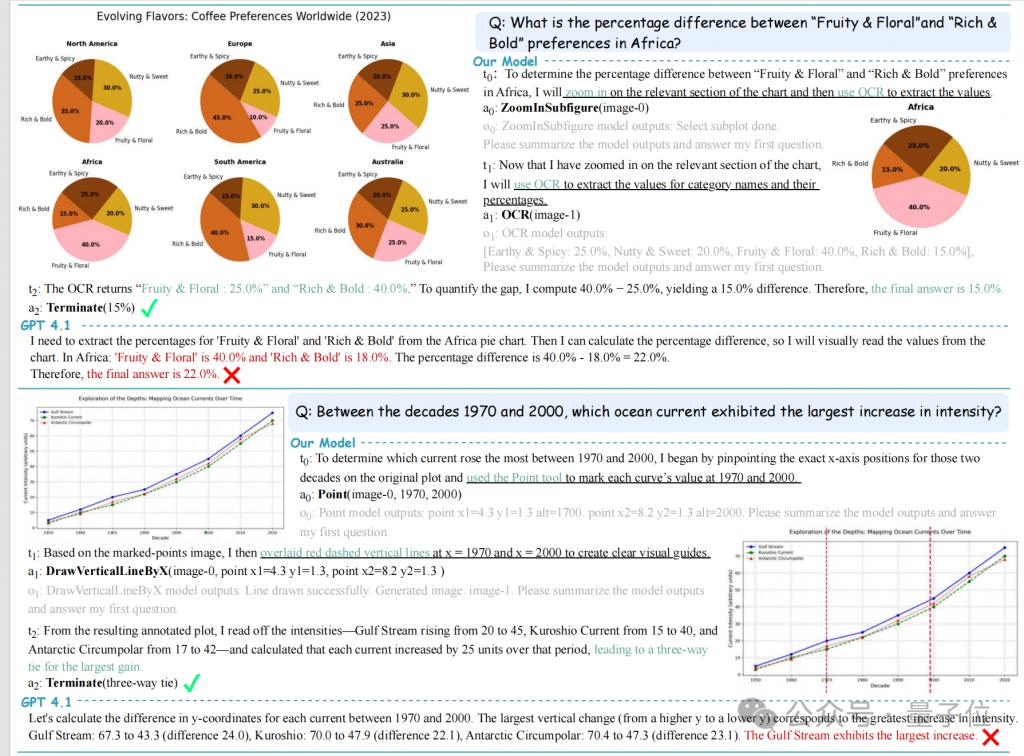
△V-ToolRL ( 上侧工具辅助 ) vs GPT-4.1 ( 下侧直接解读 )
这些案例生动地展示了 V-ToolRL 如何通过结构化的工具调用,实现比直接视觉解读更准确、更可解释的推理。
小结一下,OpenThinkIMG 框架的核心贡献在于:
1、一个开放、强大的工具部署与训练平台:解决了工具集成和智能体训练的难题。
2、内置高效数据生成方法:为模型训练提供高质量 " 燃料 "。
3、V-ToolRL 作为核心训练算法:使 AI 能够真正学会自主、智能地使用视觉工具。
团队表示,OpenThinkIMG 将为开发能够真正 " 用图像思考 " 的下一代 AI 智能体提供坚实的基础设施。
未来,他们将继续扩展 OpenThinkIMG 支持的工具和模型,探索更复杂的任务场景,并期待与社区共同推动这一激动人心的领域向前发展。
论文第一作者苏肇辰为苏州大学三年级研究生,香港科技大学准博士生,在 NeurIPS、ACL 等国际顶级会议上发表多篇研究成果。项目通讯作者为港中文成宇教授。
技术报告:
https://arxiv.org/pdf/2505.08617
GitHub 仓库:
https://github.com/zhaochen0110/OpenThinkIMG
数据集和模型:
https://huggingface.co/collections/Warrieryes/openthinkimg-68244a63e97a24d9b7ffcde9
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

点亮星标
科技前沿进展每日见